Excel列構成の整理・リファクタリング
前回の実装では、Excel出力の列に以下の問題がありました。
- 「処理2」「処理3」「処理4」という内部実装名がそのまま見出しに出ていた
- C列(CLIPスコア)とH列(CLIP生値)が同じ数値だった
- D列「総合スコア」はE〜G列から計算しているため冗長だった
そこで以下のように整理しました。
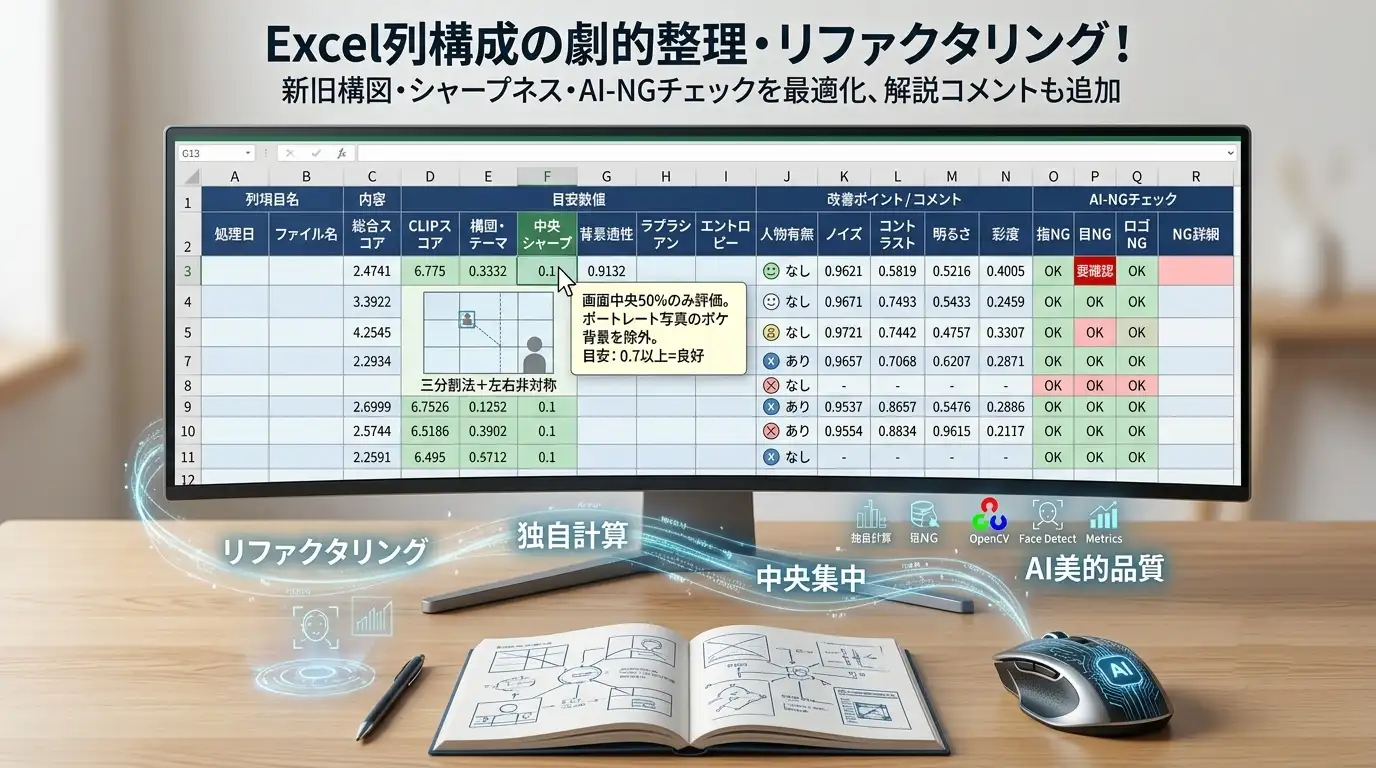
| 列 | 項目名 | 内容 |
|---|---|---|
| A | 処理日 | 解析実行日時 |
| B | ファイル名 | 元画像ファイル名 |
| C | 総合スコア | CLIP×中央シャープ×背景適性で計算 |
| D | CLIPスコア | AI美的品質スコア(1〜10) |
| E | 構図・テーマ | 三分割法+左右非対称性スコア |
| F | 中央シャープ | 画面中央50%のみ評価(ボケ背景除外) |
| G | 背景適性 | エントロピーから計算。低いほどすっきり |
| H | ラプラシアン | 全体シャープネス生値(参考) |
| I | エントロピー | 全体情報量生値(参考) |
| J | 人物有無 | 顔検出で人物の有無を判定 |
| K〜N | ノイズ/コントラスト/明るさ/彩度 | 追加品質指標 |
| O〜Q | 指NG / 目NG / ロゴNG | AI-NGチェック結果(赤セル=要目視確認) |
| R | NG詳細 | 確信度スコアと検出内容 |
「構図・テーマ」の改善
旧版ではCLIPスコアと同値で意味がありませんでした。新版では三分割法+左右非対称性から独自計算しています。被写体が片側に寄って反対側に余白がある「ストック写真らしい構図」が高スコアになります。
「中央シャープ」の改善
旧版では全体のシャープネスを計算していたため、意図的なボケ背景がある写真は低スコアになっていました。新版では画面中央50%の領域のみで評価します。ポートレートのような浅い被写界深度の写真でも正しく評価できます。
また、各列の見出しにExcelコメント(ホバーで表示)を追加しました。項目の説明・判定基準・目安数値が確認できます。
追加した画像チェック項目
CLIPスコアとシャープネスだけでは捉えきれない品質指標として、OpenCVを使った以下の4項目を追加しました。
| 項目 | 計算方法 | 目安 |
|---|---|---|
| ノイズスコア | メディアンフィルタとの差分で高周波ノイズを推定 | 0.8以上=良好 |
| コントラスト | グレースケール標準偏差ベース | 0.6以上=良好 |
| 明るさ | 平均輝度が理想範囲(100〜160)に近いほど高スコア | 0.7以上=良好 |
| 彩度 | HSV色空間のSチャンネル平均 | 0.3以上=色鮮やか |
また「顔検出数」から「人物有無(あり/なし)」に変更しました。顔の数を数えても実用上意味がなく、「人物が写っているか」という情報のほうが有用と判断したためです。
AI-NGチェック機能の実装
ストックフォト審査でNGになりやすい以下の3要素を、OllamaのマルチモーダルAIで自動検出する機能を実装しました。
| チェック項目 | 検出内容 |
|---|---|
| 指NG | 6本以上の指・明らかな変形・融合 |
| 目NG | 明らかな寄り眼・斜視・左右方向のズレ |
| ロゴNG | 読めるブランドロゴ・テキスト・透かし |
「確信度スコア制」を採用した理由
最初はtrue/falseの二択で実装しましたが、全ての画像がNGになる「過検出」が頻発しました。AIに「疑わしければNG」と判断させると、正常な画像も片っ端からNGになってしまいます。
そこで0〜10の確信度スコアを返させ、7以上のみNG判定(バランス型)に変更しました。プロンプトには「迷ったら0を返す」「ホログラム・デジタル表示はOK」「完全にボケて読めない背景文字はOK」など、具体的なOK例・NG例を列挙しています。
NG詳細列には確信度スコアも記録されます。
[指:0/目:0/ロゴ:0] → 全項目スコア低く問題なし
[指:8/目:0/ロゴ:0] 6 fingers → 指に問題あり → 要目視確認NGモデル選定の判断と結果
NGチェックに使うモデル選定は、スペック制約との戦いでした。
| モデル | VRAM目安 | 精度 | GTX 1060 3GBでの動作 |
|---|---|---|---|
| moondream | ~2GB | △ | ✅ 動く(現在使用中) |
| llava-phi3 | ~4GB | ○ | ⚠️ ギリギリ厳しい |
| llava:7b | ~5GB | ○ | ❌ 無理 |
| minicpm-v | ~6GB | ◎ | ❌ 無理 |
手元の環境はGTX 1060 3GBのため、実質的にmoondreamしか動きません。moondreamでは指の本数異常を検出できないという問題が実際のチェック結果で判明しました。明らかに指の形状がおかしい画像でも、スコアが0(異常なし)と判定されてしまいます。
なぜmoondreamでは指を検出できないのか
moondreamは超軽量モデルのため、学習データ・モデル容量ともに限られています。640pxに縮小した画像を送っても、指1本1本の細部を判断する能力が不足しています。これはモデルの根本的な限界であり、プロンプトの工夫で解決できる問題ではありません。
そこでGoogle Colabを使い、高スペックGPU(T4 / VRAM 15GB)上でllava:7bを動かすColab版を作成することにしました。
設定のJSON外部化(stockphoto.json)
それまでPythonコード内にハードコーディングされていた設定を、stockphoto.jsonに外部化しました。
JSON外部化を選んだ理由
このツールはUpscayl・NGチェック・審査結果収集など複数のスクリプトで構成されています。各スクリプトがそれぞれ設定をハードコードしていると、パスを変えるたびに複数ファイルを修正する必要があります。1ファイルで全設定を管理し、スクリプトは読み込むだけという構成にしました。
JSON管理になった主な項目は以下の通りです。
| カテゴリ | 設定項目 |
|---|---|
| パス | image_folder / output_excel / output_csv |
| Ollama | url / model_meta / model_ng / timeout_sec |
| 画像サイズ | analyze_size(OpenCV用) / meta_size(メタデータ生成) / ng_size(NGチェック) / jpeg_quality |
| NGチェック | threshold(判定閾値) / enabled(スキップ可能) |
| Excel | header_color / group_colors |
画像サイズ設定を変数化した意義
NGチェックで送信する画像サイズ(ng_size)はモデルの精度に直結します。moondreamは512〜640pxが適正ですが、llava:7bなら1024pxにすることで細部の検出精度が上がります。モデルを変えるたびにコードを修正するのでなく、JSONの数値を変えるだけで対応できます。
なお、JSON更新時には「analyzeセクションのみ更新する」という制約がありました。他のセクション(upscayl・exam_ok_ng_collectなど)を別のスクリプトが利用しているためです。json.load() → json.dump()で全体を再整形すると、1行配列が複数行に展開されてしまい、他セクションの見た目が変わってしまいます。そのため、文字列レベルでanalyzeブロックだけを差し替える方法を採用しました。
Google Colab版の作成と格闘記録
ローカルではVRAM不足でllava:7bが動かないため、Google Colab(T4 GPU / VRAM 15GB)でOllamaとllava:7bを動かすノートブックを作成しました。この過程では多くのエラーに遭遇しました。
エラー① ノートブックの開き方を間違えた
最初、.ipynbファイルをColabのコードセルに貼り付けて実行してしまい、NameError: name 'null' is not definedというエラーが発生しました。
解決策: .ipynbファイルはGoogle DriveにアップロードしてColabで開くか、「ファイル → ノートブックをアップロード」で正しく開く必要があります。JSONをコードとして実行してしまっていました。
エラー② Ollamaのインストールスクリプトが失敗
通常の curl install.sh | sh を使ったインストールは、ColabのDockerコンテナ環境ではsystemdが存在しないため失敗します。
CalledProcessError: Command 'curl -fsSL https://ollama.com/install.sh | sh' returned non-zero exit status 1.解決策: GitHubリリースからバイナリを直接ダウンロードする方式に変更しました。ただし、バージョンを固定したURLも404になることがあったため、最終的にPythonのrequestsライブラリでGitHub APIから最新バージョンのURLを取得してダウンロードする方法に落ち着きました。
エラー③ ダウンロードしたファイルがバイナリではなかった
curlでダウンロードしたファイルを確認すると、こんな結果が出ました。
/usr/local/bin/ollama: ASCII text, with no line terminatorsバイナリではなくHTML(エラーページ)がダウンロードされていました。URLのリダイレクトに対応できていなかったことが原因です。
解決策: curlではなくPythonのrequestsで直接バイナリストリームとして書き込むことで解決しました。
エラー④ パスの設定ミスによるFileNotFoundError
セル1の設定で stockphoto/results と記載していたが、Google Drive側のフォルダは ai_stockphoto/results でした。
FileNotFoundError: Cannot find file: /content/drive/MyDrive/stockphoto/results/analysis_results.xlsx解決策: セル1のパス設定を修正し、セル9(Excel出力)を再実行することで解決しました。
エラー⑤ OllamaのBINパスが見つからない
セル2でOllamaをインストールした後、セル3でbinのパスが見つからずOSErrorが発生しました。
解決策: インストール時に OLLAMA_BIN 変数にパスを保存し、セル3ではその変数を使って起動するように変更しました。セル単体で実行した場合のフォールバックとして複数の候補パスを自動検索する処理も追加しました。
Colabの重要な制約
Google Colabの無料枠はセッションが切れるとインストールしたOllama・ダウンロードしたモデル(llava:7b 約4GB)・全変数がリセットされます。Google Drive内のExcel・CSVは残ります。毎回セル1〜5を実行し直す必要があり、特にllava:7bのダウンロードで10〜15分かかります。モデルをGoogle Driveに保存して復元する対策が今後の課題です。
実際のNGチェック結果と考察
llava:7bを使ったNGチェックを実際に動かしてみました。ホログラム操作系の画像(指が変形しているもの)でも、スコアはほぼ0(正常)という結果になりました。
ただし画像をよく見ると、指の本数自体は5本で形状も比較的自然な範囲内のものが多く、「明らかにおかしい」レベルには至っていない、という見方もできます。moondreamとllava:7bでNGチェック精度を比較するには、明らかに6本指・目がおかしい画像サンプルでのテストが必要です。数をこなしてデータを蓄積してから傾向を判断することにしました。
各スコアの読み方・目安
| 指標 | 目安値 | 備考 |
|---|---|---|
| 総合スコア | 5.0以上=良好 / 3.0未満=要確認 | CLIP×シャープ×背景の掛け算 |
| CLIPスコア | 6.5以上=良好 / 5.0未満=低品質 | AI美的品質(1〜10) |
| 構図スコア | 0.5以上=良好 | 被写体が片側に寄っているほど高い |
| 中央シャープ | 0.7以上=良好 / 0.3未満=ボケあり | 中央50%のみ評価 |
| 背景適性 | 0.7以上=良好 | 低いほどすっきりした背景 |
| ラプラシアン | 200以上=シャープ | 全体の生値(参考) |
| エントロピー | 6.0〜7.5=適正 | 高すぎると背景がごちゃつく |
| ノイズスコア | 0.8以上=良好 | 低ノイズほど高い |
| コントラスト | 0.6以上=良好 | 明暗差の適正度 |
| 明るさ | 0.7以上=良好 | 暗すぎ・明るすぎを検出 |
| 彩度 | 0.3以上=色鮮やか | HSV Sチャンネル平均 |
| NGチェック確信度 | 7以上=NG(要目視確認) | 0〜10、閾値はJSON設定 |
現時点での正直な評価
NGチェックはまだ「補助ツール」の域を出ていません。llava:7bでも見逃すケースがあり、精度の高いNG検出にはさらに高精度なモデル(Gemini APIやGPT-4o Vision)が必要と感じています。一方、CLIPスコアやシャープネスなどの定量指標は実用的な精度になってきており、「明らかにスコアが低い画像を除外する」用途では十分に機能しています。
次の記事では、Adobe Stock申請後の審査結果(OK・NG)を自動収集してExcelに記録する仕組みについて紹介する予定です。
FAQ
moondreamとllava:7bの違いは何ですか?
moondreamはVRAM 2GB程度で動く超軽量モデルですが、指の本数異常など細部の判定精度が低いです。llava:7bはVRAM 5〜7GB必要ですが、画像の細部をより正確に判定できます。NGチェックの用途にはllava:7b以上を推奨します。
Google ColabでOllamaは動きますか?
動きますが、通常のインストールスクリプト(install.sh)はColab環境では失敗します。GitHubリリースからPythonのrequestsでバイナリを直接ダウンロードする方法が有効です。またセッションが切れるたびに再インストールが必要になる点も注意が必要です。
NGチェックの確信度スコアとは何ですか?
0〜10のスコアでAIがNGの確信度を返します。7以上をNG判定(バランス型)にすることで、正常な画像を誤ってNGにする過検出を大幅に減らせます。閾値はstockphoto.jsonで変更可能です。
stockphoto.jsonで何が設定できますか?
入出力パス、Ollamaのモデル・URL・タイムアウト、NGチェック用の画像送信サイズ・JPEG品質、NG判定閾値・有効無効、Excelの配色設定などが外部から設定できます。Pythonコードを触らずに動作をカスタマイズできます。