全体設計の概要
Adobe StockはAPIを一般公開していないため、審査状況のデータを直接取得する手段がありません。 そこで、ログイン済みのChromeブラウザをリモートデバッグで操作し、審査ページのデータをPythonで収集する方法を採用しました。
収集するCSVは3種類です。
| CSV種別 | 収集元ページ | キー列 | 主な情報 |
|---|---|---|---|
| EXAM CSV | 審査中ページ | filename / file_id | 申請中ファイル一覧・経過日数 |
| OK CSV | ポートフォリオページ | file_number | 承認済みファイル・承認日 |
| NG CSV | NGページ | file_id / filename | 非承認ファイル・NG理由 |
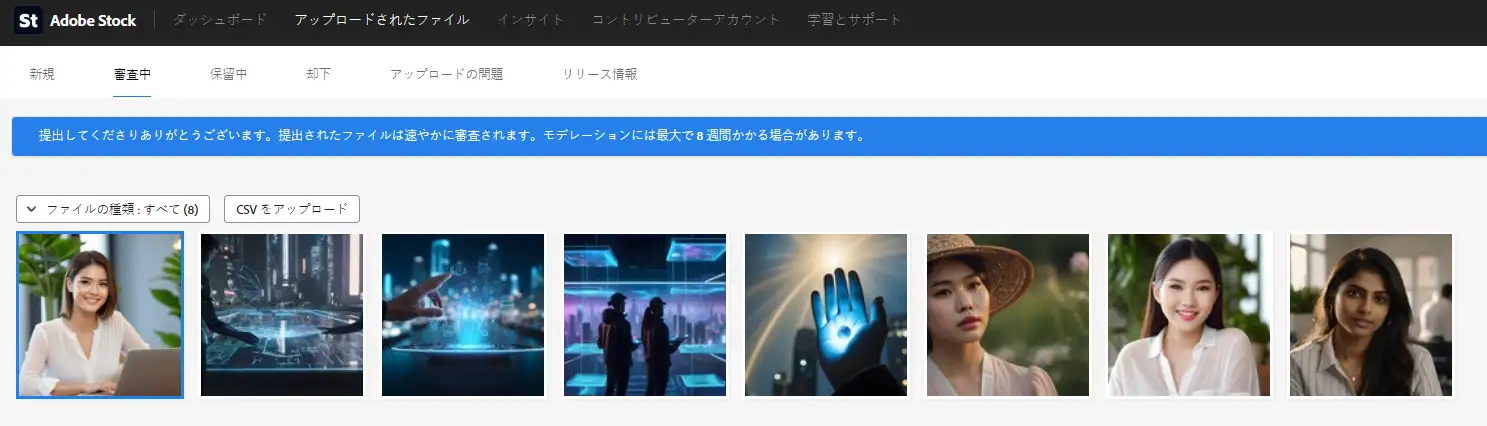
下図はAdobe Stockのサイトとなります。 審査中タブの内容をEXAM、ダッシュボードタブの内容をOK、却下タブの内容をNGとして収集します。
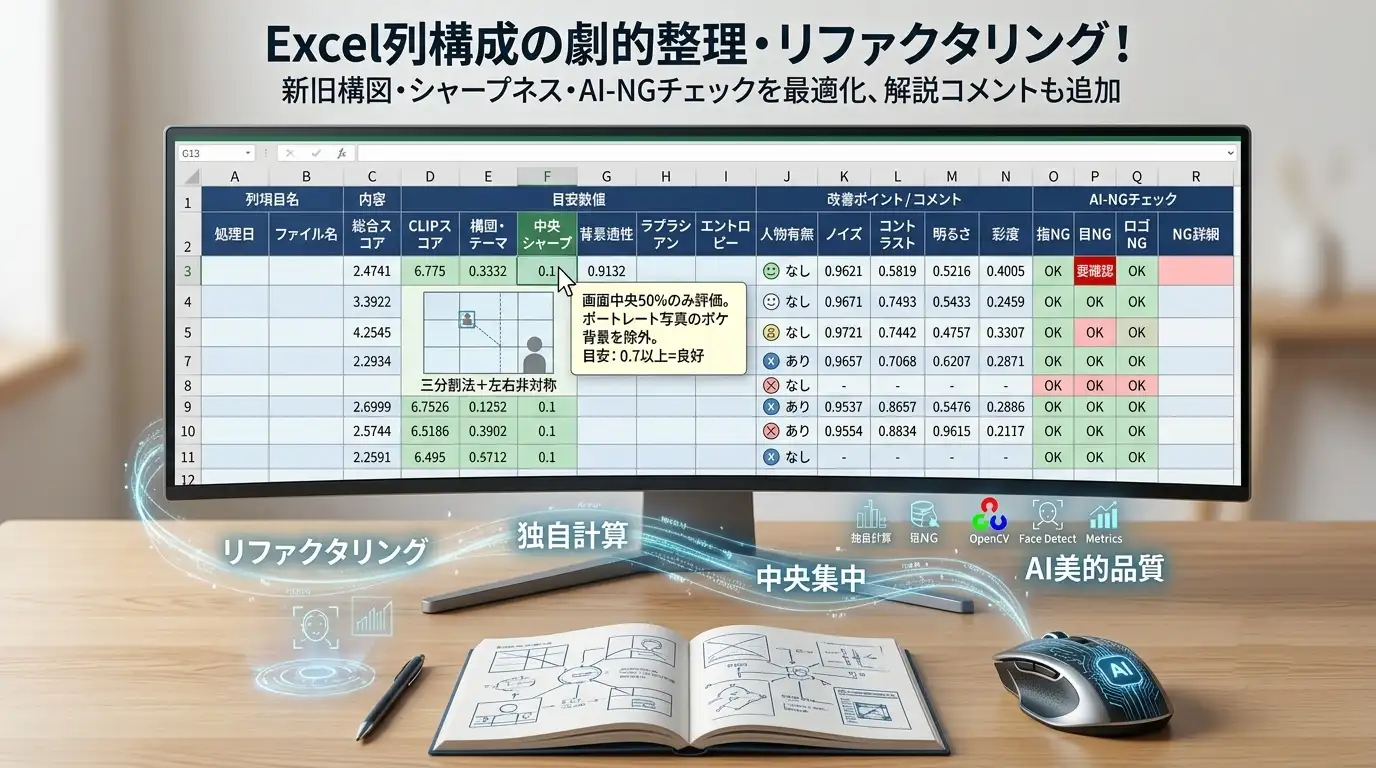
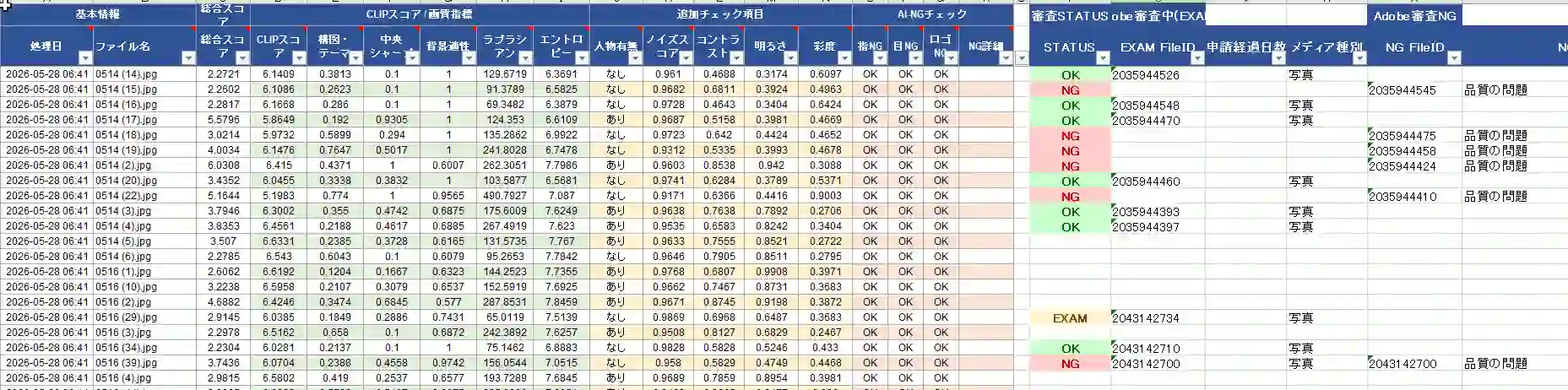
収集したCSVは、Pythonスクリプトで解析結果Excelの「解析結果」シートに書き込まれます。 ExcelのT列にSTATUSとして EXAM / OK / NG / 空白 が記録され、フィルタで一覧管理できます。
以下のようなイメージとなります。
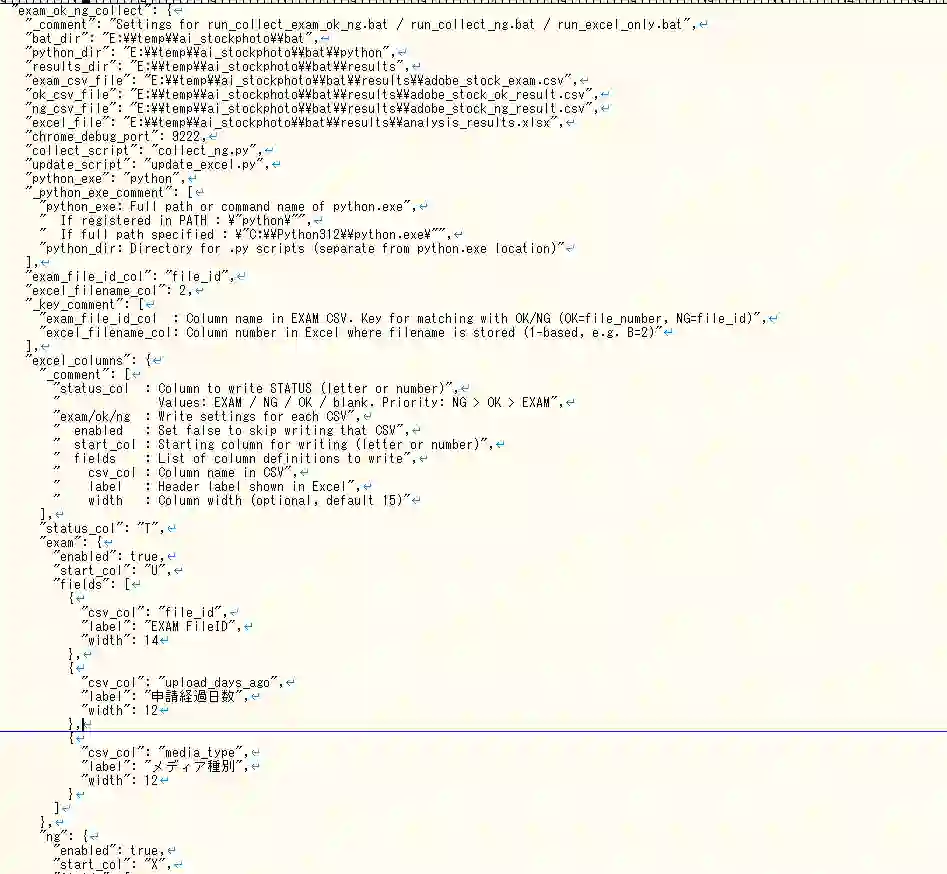
設計のポイント:全設定をJSONに集約
ファイルパス・CSV列名・Excel書き込み列・chrome_debug_portまで、すべてstockphoto.jsonに集約しています。
スクリプト本体を触らずにJSONだけで設定変更できるため、環境移行や列の追加が容易です。
以下のようなイメージとなります。少なくとも出力先や入力先は設定ファイルにした方が便利だと思います。
Chrome拡張でのCSV収集
収集スクリプトはChromeのリモートデバッグポート(デフォルト: 9222)経由でブラウザを操作します。 事前にChromeを以下のオプションで起動し、Adobe Stockにログインしておく必要があります。
私は普段からChromeを使用しているので、別プロセスとして起動しておくイメージです。そうすることで、通常使用しているブラウザで作業する必要はありません。
Chrome起動コマンド例
chrome.exe --remote-debugging-port=9222
ログイン後、batメニュー(後述)から収集を実行します。ポート番号はstockphoto.jsonのchrome_debug_portで変更できます。
3種のCSV収集スクリプト(collect_exam.py / collect_ok.py / collect_ng.py)は、
それぞれ対応するページをスクロールしながらデータを収集し、CSVとして出力します。
また、処理したタイミングの各CSVとは別に履歴を蓄積したCSVにも追記するようにしています。(次記事で紹介)
下図のようなイメージです。
Adobeのダッシュボードからは、filename(ローカルで管理していたファイル名)を取得できないという制約があります。 承認後のポートフォリオページには file_number(Adobe Stock側の管理ID)しか表示されないためです。 この制約がのちの突合設計に大きく影響します(後述)。
3種のCSVとExcelの突合設計
ExcelへのSTATUS書き込みは、ファイル名でCSVとExcelを照合する方式です。ただし3種のCSVはそれぞれ持つキー情報が異なるため、突合方法を工夫しています。
| CSV | 突合キー | 照合先 |
|---|---|---|
| EXAM | filename | Excel B列(ファイル名)と直接照合 |
| NG | file_id または filename | filename → Excel B列、次にfile_id → Excel U列(EXAM FileID) |
| OK | file_number | Excel U列(EXAM FileID)と照合 |
EXAM.CSVです。一番左の項目がfile_number、左から2番目の項目がfilename(ローカルファイル名)となります。

OK.CSVです。一番左の項目がfile_number項目となり、filename(ローカルファイル名)項目は存在しません。
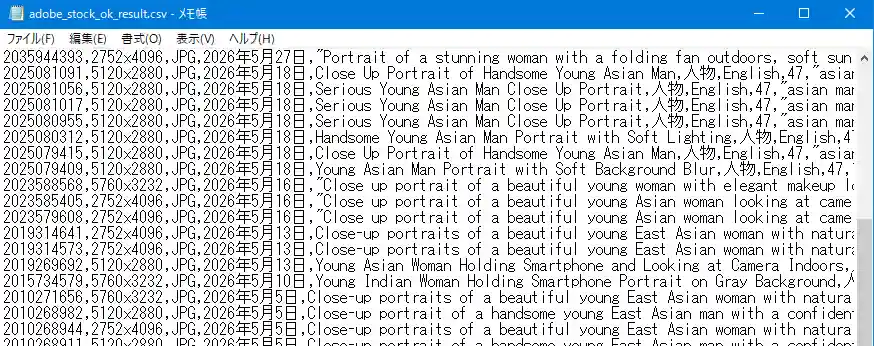
NG.CSVです。一番左の項目がfile_number、左から2番目の項目がfilename(ローカルファイル名)となります。

OKの突合が特殊な理由は、先述の通りOK CSVにfilenameが存在しないためです。 当初はEXAM CSV経由でfile_idからfilenameを引こうとしましたが、 OKになった画像はEXAMページから消えるというAdobe側の仕様により、EXAM CSVに存在しない = filename解決できない、という問題が発生しました。
OK突合問題の解決策
EXAMスクリプトがExcelに書き込む際、U列にEXAM FileIDを記録します。 OKスクリプトはEXAM CSVを介さず、ExcelのU列と ok_history の file_number を直接照合します。 これにより「5/29にEXAMとして登録 → 5/30にOKになってEXAMから消えた」画像も正しくOKと記録できます。
STATUS優先度の設計
3種のCSVを別々のタイミングで収集・反映するため、STATUSの上書き優先度を明確に定義しています。
| STATUS | 意味 | 上書きルール |
|---|---|---|
| NG | 審査非承認 | 最優先。EXAM行も上書きする |
| OK | 審査承認 | NGでなければ上書きする |
| EXAM | 審査申請中 | OK/NGが未設定の場合のみ書き込む |
| 空白 | 未収録 / 手動保護 | いずれのCSVにも存在しない行 |
また、STATUSがすでにOKまたはNGの行は一切更新しないというルールも設けています。 手動でOK/NGを入力した行も自動処理の対象外となるため、過去データを安心して手動管理できます。 NGだった画像を再審査に出した場合は、手動でSTATUSを空白に戻すことで再度更新対象になります。
batメニューによる統合操作
すべての処理は 下図のバッチファイルメニューから操作します。下図はbat起動直後の画面です。幾つかの処理があるので、メニュー形式にしています。
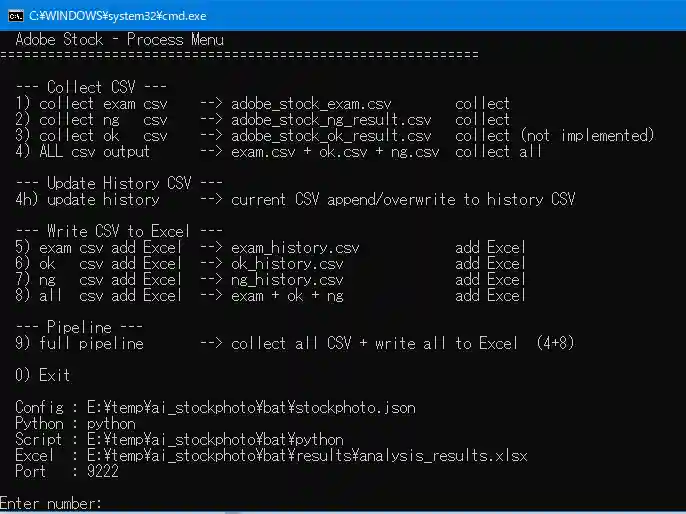
| 番号 | 処理内容 |
|---|---|
| 1 | EXAM CSV収集 → history自動更新 |
| 2 | NG CSV収集 → history自動更新 |
| 3 | OK CSV収集 → history自動更新 |
| 4 | 全CSV収集(exam + ok + ng)→ history更新 |
| 4h | history更新のみ(手動追加後などに使用) |
| 5〜7 | 各CSV → Excel書き込み |
| 8 | 全CSV → Excel書き込み(EXAM → OK → NG順) |
| 9 | 全収集 + history更新 + 全Excel書き込み(フルパイプライン) |
| 0 | 終了 |
8) の実行順序が重要な理由
EXAM → OK → NG の順に実行することで、STATUS優先度が正しく反映されます。 最後にNGを書き込むことで「EXAMとしてすでに記録されていてもNG判定で上書き」が確実に行われます。
bat起動時にメニュー画面下部に Config / Python / Script / Excel / Port の現在値が表示されます。 JSONの読み込みが正しくできているか起動直後に確認できるため、設定ミスの早期発見に役立ちます。
発生したエラーと解決策
正直時間も要しましたし、苦労しました。自動化の恩恵とペイできない・・・のは置いときましょう(笑)。
エラー1:「Failed to load settings from stockphoto.json」
batの起動時にJSONの読み込みに失敗するエラーです。 PowerShellでJSONを読み込む際、日本語のechoメッセージが文字コード(UTF-8 vs CP932)の混在を引き起こしていました。
解決策として、bat内のecho・メッセージを全て英語に統一しました。
また、PowerShellのfor /f 構文に usebackq と -Encoding UTF8 オプションを追加し、
パスにスペースが含まれる場合も安定して動作するよう修正しました。
エラー2:OKが1件も書き込まれない
8) の全書き込みを実行してもSTATUSのOK件数が0件のままという状況です。 調査したところ、OK CSVの file_number とEXAM CSVの file_id の一致件数は69件中8件のみで、 残り61件はEXAMとfile_idが一致しないためfilename解決に失敗していました。
原因を追うと、OKになった画像はAdobeのEXAMページから消えるため、 収集タイミングによってはEXAM CSVにそもそも存在しないことがわかりました。 8件が一致するのは、EXAMからOKになる過渡期のデータが偶然残っていた分です。
完全な設計ミスでした。この問題は次記事で紹介するhistory設計により根本的に解決しています。
エラー3:collect_ng.py が起動しない(改行コードの問題)
batファイルをダブルクリックしても画面が一瞬出て閉じるだけで、何もメッセージが出ないという現象が起きました。 原因は、生成したbatファイルの改行コードが LF(Unix形式) になっていたためです。 Windowsのバッチファイルは CRLF でなければ正しく解釈されません。
解決策として、ファイルをSublime TextやVS Codeで開いてCRLFに変換するか、
コマンドラインで sed -i 's/$/
/' ファイル名.bat を実行します。
以来、batファイルを生成・受け取った際は改行コードを必ず確認するようにしました。
エラー4:NGページで無限ループ(ページ遷移が「1→1」のまま)
collect_ng.py を実行すると、全タイルをスキップしたままページ遷移を繰り返す無限ループが発生しました。
コンソールを確認すると「ページ遷移 1 → 1」が永遠に繰り返されており、最終ページに到達できていない状態でした。
原因は2点ありました。1点目は go_to_next_page() 内で「次へ」クリック後にページ番号が実際に変わったかを確認せず
True を返していたこと。2点目は internal_id がフォールバック値(p{page}_{i}形式)になっている場合、
2周目に同じIDが collected_ids に登録済みとして全タイルがスキップされてしまうことです。
解決策:ページ変化を確認してから Trueを返す
遷移後に get_current_page() を再取得し、前のページ番号と一致していれば False(最終ページ)として終了するよう修正しました。
また安全上限として while True を while page <= 500 に変更し、デバッグ用にページネーターの表示テキストもコンソール出力するようにしました。
FAQ
審査結果をExcelで管理するメリットは何ですか?
スコアと審査結果を同じExcelで管理することで、「どのスコア帯でNGが多いのか」「どのジャンルが通過しやすいのか」といった傾向分析が可能になります。 データが蓄積されるほど分析精度が向上し、次回以降の画像選別にも活用できます。
Chrome拡張でCSVを収集する理由は何ですか?
Adobe Stockは審査状況やポートフォリオ情報を取得する一般向けAPIを公開していません。 そのため、本システムではログイン済みのChromeブラウザをリモートデバッグで操作し、審査状況ページから必要な情報を収集しています。
OKになった画像がEXAMページから消えても追跡できますか?
はい、追跡できます。本ツールではEXAM収集時に取得したFileIDをExcelへ保存しているため、OKになってEXAMページから消えた後でも、 Excelに保存されたFileIDとOK履歴データを照合し、STATUSを正しくOKへ更新できます。