この記事は、以下のような方を想定しています。
- 株式投資で信用取引の規制情報を追いかけている方
- 個人開発でデータ収集・可視化サイトを作りたい方
- Pythonでスクレイピング・データマージを学びたい方
- Pandasのマージ処理でハマった経験がある方
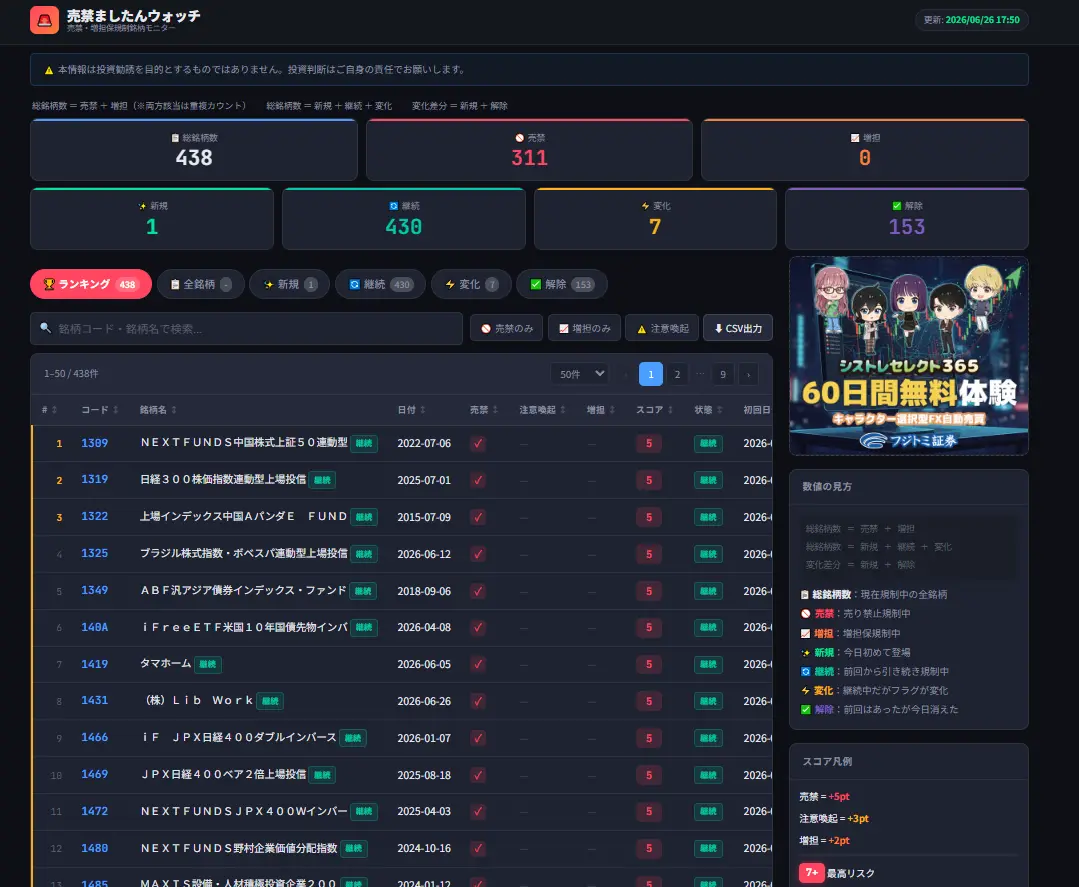
個人で運用しているサイトの一つに「売禁ましたんウォッチ」というものがあります。 日証金が発表する貸借取引制限(いわゆる「売禁」)と、JPXが発表する信用取引の増担保規制(「増担」)を毎日監視し、 新規・継続・解除の動きを一覧で確認できるツールです。
構築したサイトは以下の内容となり、Windowsタスクスケジューラを利用して毎日自動更新しています。 このシステム構築時に苦労した点や工夫した点を記事にしておき、似たようなことを考えておられる方の参考になれば幸いです。
株式投資をしていると、銘柄が急騰したタイミングで「売禁」や「増担」がかかることがあります。 これは投機的な値動きを抑制するための規制ですが、裏を返せば「市場が注目している銘柄」のシグナルでもあります。 個人的にこの情報を毎日チェックしたかったのですが、公式サイトは表形式の一覧しか提供しておらず、 過去との比較や新規追加の検知が手作業では非常に煩雑でした。そのため、時間も要していました。
作ったもの:売禁ましたんウォッチ
システム化による作業効率化の比較
手作業で行っていた頃は、毎日合計で約30分の時間がかかっていましたが、システム化(自動化)したことで、 現在は1日わずか5分(最終確認のみ)の作業に短縮されました。
| 作業工程 | システム化前(手作業) | システム化後(自動化) |
|---|---|---|
| サイトへのアクセス・ファイルDL | 5分 | Pythonで全自動処理 (手作業 0分) |
| 過去のExcelデータへの蓄積・転記 | 5分 | |
| 前日の情報との差分・変化の比較 | 10分 | |
| データ内容の最終的な目視確認 | 10分 | 5分(サイトを開いてチェックするだけ) |
| 合計所要時間 | 約30分 | 約5分 (83%の時間短縮!) |
完成したサイトの概要は以下の通りです。
| 項目 | 内容 |
|---|---|
| データ更新 | 1日1回、Pythonスクリプトで自動取得 |
| 対象データ | 日証金の貸借取引制限(売禁・注意喚起)、JPXの増担保規制 |
| 表示機能 | ランキング・全銘柄・新規・継続・変化・解除の6タブ |
| 差分管理 | 前回処理日と比較し、新規/継続/変化/解除を自動判定 |
| フロントエンド | 静的HTML+JavaScript(CSVを読み込んで描画) |
なぜ自作したのか
既存の株式情報サイトでも増担保や売禁の情報は見られますが、「いつ新規に規制されたか」「いつ解除されたか」を 履歴として追える形で、かつ見やすい形で提供しているサービスは見当たりませんでした。そこで自分にとって見やすい形でまとめるサイトを構築してみよう!となりました。 また、データを履歴として蓄積しておけば、将来的な分析にも役立つと考えたことも理由の一つです
個人開発で重視したのは以下の3点です。
- 毎日自動で動く(手作業ゼロ)
- 過去との差分が一目でわかる(新規・解除のハイライト)
- スマホでも見やすい(外出先でもチェックできる)
データソースの選定
規制情報の取得元として、以下の2つの公式サイトを利用しています。この点は手作業時代も変わりません。
このサイトから毎日自動でアクセスしてファイルダウンロードする仕組みをChatGPTやClaudeを活用しながら、試行錯誤して完成させました。
しかしながら、日証金のページはJavaScriptでテーブルが描画される構成だったため、単純なrequestsでは
表データを取得できませんでした。そのためSeleniumでヘッドレスブラウザを起動し、テーブルのレンダリングを待った上で
HTMLを取得する方式を採用しています。一方JPXのページは静的HTMLでテーブルが出力されていたため、
pandas.read_html()だけで十分でした。目に見えるブラウザを起動してそのブラウザの内容を取得するのはイメージしやすいですが、
ブラウザが表示完了するまで取得処理を待つという点とその処理をヘッドレスブラウザ(目に見えないブラウザ)で対応できることを知ったのは今回の対応でした。
データ取得処理の実装コード(イメージ)
実際に作成したデータ取得部分のロジックです。Seleniumによるヘッドレスブラウザでの描画待機を本命としつつ、エラー発生時には通常のrequests処理へと流れる二段構えの設計にしています。
def _fetch_with_selenium():
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
options = Options()
options.add_argument("--headless=new") # 安定性の高い新しいヘッドレスモード
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36")
options.add_argument("--window-size=1920,1080") # レンダリング崩れを防ぐサイズ指定
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)
try:
driver.get(URL)
wait = WebDriverWait(driver, 20)
wait.until(EC.presence_of_element_located((By.TAG_NAME, "table")))
time.sleep(3) # JavaScriptの描画完了を待つ
html = driver.page_source
finally:
driver.quit()
return _parse_html(html)
def _fetch_with_requests():
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
resp = requests.get(URL, headers=headers, timeout=30)
resp.raise_for_status() # エラー時は例外を発生させてフォールバックへ
resp.encoding = resp.apparent_encoding
return _parse_html(resp.text)スクレイピング設計時に意識したポイント
- サイト構造が変わってもある程度耐えられるよう、列名は「コード」「銘柄」などキーワード検索で動的に特定
- Selenium起動失敗時はrequestsへフォールバックする二段構成
- 取得失敗時は空のDataFrameを返し、後続処理がエラーで落ちないようにする
スクレイピングの実装
日証金側の取得処理は、おおまかに以下の流れです。
- Seleniumでヘッドレスブラウザを起動し、対象URLにアクセス
WebDriverWaitでテーブル要素の出現を待機driver.page_sourceでHTMLを取得し、pandas.read_html()でテーブル化- 列名に「コード」「銘柄」「措置」「内容」「通知」などのキーワードが含まれる列を検索して抽出
- 「実施内容」に「売」という文字列が含まれるかで売禁フラグを設定
- 「措置内容」に「注意」という文字列が含まれるかで注意喚起フラグを設定
JPX側は増担保規制の対象銘柄一覧が静的テーブルとして出力されているため、こちらは非常にシンプルです。 テーブルの列数が変わるケースに備えて、列数に応じて列名の割り当てを分岐させる処理を入れています。 また「実施日」(増担保が開始された日付)は、後続の解除予定日計算で重要な役割を持つため、 日付型に正規化して保持するようにしています。
マージ処理でハマった列名衝突
日証金データとJPXデータは、どちらも「コード」「銘柄」という列を持っています。
そのためpd.merge()でそのまま結合すると、両方に存在する列に対して自動で
サフィックスが付与され、銘柄_taisyakuと銘柄_jpxのような列名になってしまいます。
さらに厄介だったのは、日証金側にも「実施日」に相当する列があったケースです。
このときJPX側の「実施日」(増担保の開始日)と意図せず衝突し、実施日_jpxという列名になって、
後続処理から「実施日」列として参照できなくなっていました。結果として増担保の実施日がCSV上ですべて空欄になる
という不具合を起こしてしまいました。
解決した方法
マージを実行する前に、JPX側の「実施日」をあらかじめ「増担実施日」という一時的な列名にリネームしておき、
マージ完了後に「実施日」へ戻す、という2段階の処理にしました。同名列の衝突はmerge()のオプションで
制御するより、マージ前に列名を完全に分離してしまうほうが事故が起きにくいという実感を得ました。
スコアリングの考え方
マージ後のデータには、規制の重さを点数化した「スコア」列を追加しています。複数の規制が重複している銘柄ほど 注目度が高いと考え、以下のように単純な加点方式にしました。
| フラグ | 点数 | 意味 |
|---|---|---|
| 売禁 | +5pt | 信用新規売りが禁止される、最も強い規制 |
| 注意喚起 | +3pt | 規制の前段階として発表される警告 |
| 増担 | +2pt | 信用取引の担保金率が引き上げられる規制 |
このスコアを使ってランキングを作成すれば、「複数の規制が重なっている注目銘柄」を一目で確認できます。 次回の記事では、このマージ済みデータを使って「新規・継続・変化・解除」を判定する差分検出ロジックと、 その実装で実際にハマったバグの実録を紹介します。
FAQ
売禁・増担保とは何ですか?
売禁(売り禁止)は信用取引で新規の売り注文ができなくなる規制、増担保(増担)は信用取引の担保金率が引き上げられる規制です。 いずれも日証金やJPXが投機過熱を抑えるために発動します。
日証金とJPXのデータはどこで確認できますか?
日証金は公式サイトの貸借取引制限ページ、JPXは信用取引規制のページで公開されています。 ただし表形式での提供のみで、履歴管理や差分抽出は自分で実装する必要があります。
PandasのDataFrameをマージする際の注意点は?
同名列が複数存在する場合、pd.merge()のsuffixesオプションで意図しない列名変化が起きやすいです。
マージ前に列名を整理し、衝突を避ける設計が重要です。