
なぜ信用残データを自動収集しようと思ったか
株式投資をしているとよく「信用残」という言葉を聞きます。信用取引で買っている人・売っている人がどれだけいるかを示すデータで、需給の偏りを考える際に欠かせない情報です。
「取組比率が0.1倍なら空売りが多くて踏み上げリスクが高い」「買残が急増しているなら将来の売り圧力になる」といった形で使われます。証券会社のサイトや株探などでも確認できますが、毎日の変化を追って履歴を蓄積し、自分なりの分析ができる環境が欲しいと思ったのがきっかけです。
JPX(日本取引所グループ)は「個別銘柄信用取引残高」を毎営業日公開しています。全銘柄まとめてXLSファイルで配布されているので、これをPythonで自動取得・蓄積すれば、好きなタイミングで好きな切り口で分析できます。
このシリーズで作るもの
- JPXからXLSを毎日自動ダウンロードするPythonスクリプト
- pandas DataFrameをpickleで日次蓄積する履歴管理の仕組み
- 需給シグナル(踏み上げ候補・悪化警戒など)を自動計算するロジック
- 全銘柄をフィルタ・ソートできるHTMLダッシュボード
- 銘柄クリックでTradingViewの日足チャートを表示するモーダル
JPXの信用残データとは
JPXが公開している「個別銘柄信用取引残高(Outstanding Margin Trading by Issue)」は、東京証券取引所の全信用取引銘柄について、週次(毎週木曜日が基準日)の残高情報をまとめたものです。
ファイルは https://www.jpx.co.jp/markets/statistics-equities/margin/index.html からXLS形式でダウンロードできます。ファイル名は mtdailyk20260416.xls のような形式で、日付が含まれます。
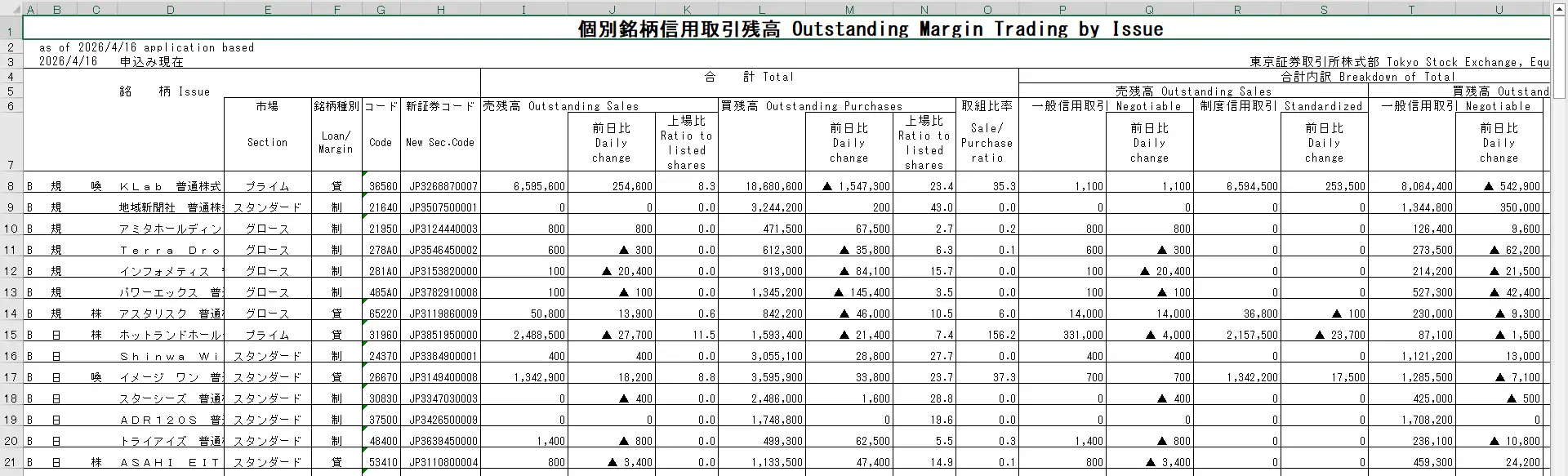
XLSの構造は少し特殊です。1〜7行目がヘッダ領域で、実際のデータは8行目(row index 7)から始まります。列は23列あり、主な項目は以下のとおりです。
| 列番号(0始まり) | 内容 | 備考 |
|---|---|---|
| 0 | フラグ1(「B」など) | 規制フラグ |
| 1 | フラグ2(「規」など) | 規制種別 |
| 2 | 注意銘柄フラグ(「喚」など) | 注意喚起 |
| 3 | 銘柄名 | 全角文字 |
| 4 | 市場(プライム・スタンダード・グロース等) | |
| 5 | 銘柄種別(貸・制) | 貸借・制度 |
| 6 | 銘柄コード(5桁) | 末尾0付き形式 |
| 7 | 新証券コード(ISINコード) | |
| 8〜 | 売残高・買残高・取組比率など | 数値 |
また、ファイルの B3セル(row 2, col 1)にデータ公表日が入っています。これをパースして「いつのデータか」を記録します。
実際のデータは下図のようなイメージです。
Pythonスクリプトの全体設計
スクリプトは1ファイル(jpx_margin_collector.py)にまとめました。処理の流れは以下のとおりです。
処理フロー
- JPXのindexページをrequestsでスクレイピングし、XLSのURLを抽出
- XLSファイルをダウンロードしてローカルに保存
- xlrdでXLSをパース、B3セルから公表日を取得、8行目以降をデータとして読み込む
- 各列を定義した列名でpandas DataFrameに変換
- 既存のPKLファイルを読み込み、同日付のデータがあれば上書き、なければ追記
- PKLに保存(履歴蓄積)、当日分CSVも出力
毎日実行することを前提に、「同じ日付を再実行しても正しく上書きされる(べき等)」設計にしています。タスクスケジューラからの自動実行でも安全です。
主な依存ライブラリは xlrd(XLS読み込み)、pandas(DataFrame操作)、pickle(履歴保存)、requests(ダウンロード)のみで、標準的な構成です。
XLSパースのポイント:銘柄コードと日付
このXLSのパースでいくつかハマりどころがありました。
① 銘柄コードは5桁、表示は4桁
JPXのXLSに入っている銘柄コードは末尾に0が付いた5桁形式です(例:14190、135A0)。実際の証券コードは末尾の0を取り除いた4桁です(1419、135A)。
近年はアルファベットを含む新しいコード体系(135A0 → 135A)の銘柄が増えています。単純に「数字5桁か否か」で判定すると新コード体系の銘柄が変換されないため、「全コードは末尾が0なので、末尾1文字を削除する」 という統一ルールで対応しました。
# 銘柄コード変換: 全コード末尾0を削除
# 13250 → 1325, 135A0 → 135A
def display_code(code):
if not code:
return code
return code[:-1] if code.endswith('0') else code② B3セルの日付はxlrdのシリアル値
XLSのB3セルには日付が入っていますが、xlrdで読むと浮動小数点のシリアル値(例:46128.0)として返ってきます。xlrd.xldate_as_datetime() で変換する必要があります。
import xlrd
wb = xlrd.open_workbook(xls_path)
sh = wb.sheet_by_index(0)
b3_val = sh.cell(2, 1).value
if isinstance(b3_val, float):
pub_date = xlrd.xldate_as_datetime(b3_val, wb.datemode).date()
③ 数値列はfloat、空欄は空文字で返ってくる
売残高・買残高などの数値は float で返ってきますが、空欄セルは空文字列になります。pd.to_numeric(..., errors='coerce') で一括変換すると安全です。
PKLによる履歴蓄積の仕組み
毎日のデータを「履歴として蓄積する」のが今回の核心です。CSVでも蓄積できますが、pandas DataFrameをpickle(.pkl)で保存すると型情報が保持され、読み込みも高速です。
蓄積のロジックはシンプルです。
import pickle
import pandas as pd
PKL_FILE = "jpx_margin_data/margin_history.pkl"
def load_history():
"""既存のpklを読み込む。なければ空のDataFrameを返す"""
if Path(PKL_FILE).exists():
with open(PKL_FILE, "rb") as f:
return pickle.load(f)
return pd.DataFrame()
def save_history(df):
with open(PKL_FILE, "wb") as f:
pickle.dump(df, f)
# 当日データを取得
df_new = parse_xls(xls_path)
pub_date = df_new["データ公表日"].iloc[0]
# 同一日付を除外してから追記(べき等)
df_history = load_history()
df_history = df_history[df_history["データ公表日"] != pub_date]
df_combined = pd.concat([df_history, df_new], ignore_index=True)
df_combined = df_combined.sort_values(["データ公表日", "銘柄コード"])
save_history(df_combined)
また、HTMLビューアからブラウザで読み込めるよう、PKLをCSVにも変換して出力します。
# PKL → CSVに変換(HTMLビューアで読み込むため)
df_combined.to_csv(
"jpx_margin_data/history.csv",
index=False,
encoding="utf-8-sig"
)
ディレクトリ構成
jpx_margin_data/
├── margin_history.pkl # 全履歴(日付追記方式)
├── history.csv # HTMLビューア用CSV(PKLと同期)
├── xls/mtdailyk*.xls # ダウンロードしたXLS
└── csv/margin_YYYYMMDD.csv # 日付別CSV実際は下図のように運用しています。



最初にハマったポイント
実際に動かしてみると、いくつかトラブルがありました。同じ状況になった方の参考になれば幸いです。
タスクスケジューラから実行すると別の場所にPKLが作られる
最初にハマったのがこれです。スクリプト内でPKLのパスを相対パスで書いていたため、タスクスケジューラから実行すると作業ディレクトリが変わり(C:\Windows\System32になることがある)、PKLが見つからず毎回空のDataFrameから始まってしまいました。
解決策はスクリプト自身の場所を基準にした絶対パスを使うことです。
from pathlib import Path
# スクリプトのあるディレクトリを基準にする
BASE_DIR = Path(__file__).parent
DATA_DIR = BASE_DIR / "jpx_margin_data"
PKL_FILE = DATA_DIR / "margin_history.pkl"
batファイルのPython実行でエラーコードが拾えない
goto :check_result を使うとERRORLEVELがリセットされてしまうことがあります。batファイルはシンプルに書くのが正解です。詳しくはシリーズ第2回で解説します。
Windowsのpython3 -cでセミコロン区切りが使いにくい
コマンドプロンプトで python3 -c "import pickle; ..." と書くと、引用符やセミコロンの扱いでエラーになることがあります。変換処理は小さなPythonスクリプトファイルに切り出して py script.py で実行するほうが確実です。
FAQ
JPXの信用残データはどこから取得できますか?
JPX(日本取引所グループ)の統計・レポートページ(https://www.jpx.co.jp/markets/statistics-equities/margin/index.html)から毎営業日XLS形式で公開されています。Pythonでページをスクレイピングし、XLSのURLを正規表現で抽出してダウンロードできます。
信用残データの銘柄コードはなぜ5桁なのですか?
JPXのXLSに収録されているコードは末尾に0を付けた5桁形式(例:14190、135A0)です。実際の証券コードは末尾の0を除いた4桁(1419、135A)で、株探やみんかぶなどの検索にはこちらを使います。近年増えているアルファベット入りの新コード体系(135A など)も同じルールで変換できます。
なぜpickle(pkl)を使うのですか?
pandas DataFrameをpickleで保存すると、列の型情報やインデックスを保持したまま高速に読み書きできます。毎日データを追記・蓄積する履歴管理用途に適しています。ただし他のツールとの互換性はCSVのほうが高いため、CSVも同時に出力して両者を用途で使い分けています。



