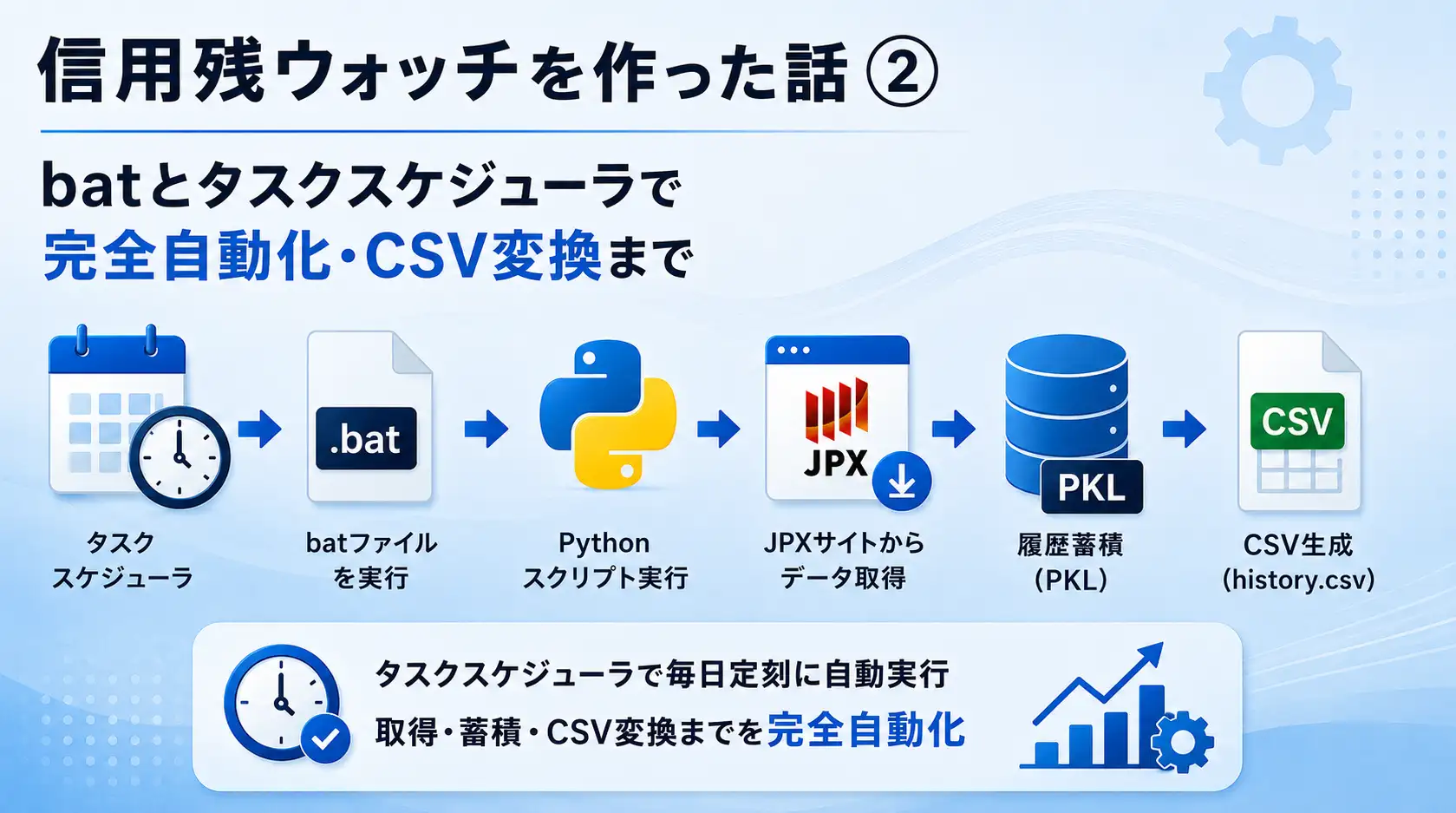
前回(第1回)でJPXの信用残データをPythonで取得・PKLに蓄積する仕組みを作りました。今回はそれを毎日自動で動かす仕組みを整えます。Windowsのタスクスケジューラ+batファイルを使った自動実行で、何度かハマったポイントを記録しておきます。
batファイルで自動実行する基本構成
Pythonスクリプト(jpx_margin_collector.py)を毎日定刻に実行するために、batファイルを経由させてタスクスケジューラに登録しました。batファイルを挟む理由は、ログ出力とエラーハンドリングをバッチ側で管理したかったからです。
最初に作ったbatファイルはこのようなものでした。
@echo off
setlocal
cd /d %~dp0
set LOGFILE=%~dp0jpx_margin_collector_bat.log
echo [%DATE% %TIME%] ===== pipeline start ===== >> "%LOGFILE%"
where py >nul 2>&1
if %ERRORLEVEL% NEQ 0 (
echo [%DATE% %TIME%] ERROR: Python not found >> "%LOGFILE%"
exit /b 1
)
py "%~dp0jpx_margin_collector.py" >> "%LOGFILE%" 2>&1
if %ERRORLEVEL% EQU 0 (
echo [%DATE% %TIME%] SUCCESS >> "%LOGFILE%"
) else (
echo [%DATE% %TIME%] ERROR code=%ERRORLEVEL% >> "%LOGFILE%"
)
exit /b %ERRORLEVEL%ポイントは cd /d %~dp0 でbatファイル自身のディレクトリに移動していること、%~dp0 でパスを絶対指定していること、標準出力・エラー出力を両方ログに書き出していることです。
タスクスケジューラの落とし穴:作業ディレクトリ問題
batをダブルクリックで実行すると正常に動くのに、タスクスケジューラから実行するとデータが蓄積されないという問題が発生しました。ログを確認すると、こんな状態になっていました。
[2026/04/20 17:40:00] ===== pipeline start =====
JPXサイトからURLを取得中...
URL: https://www.jpx.co.jp/.../mtdailyk2026041700.xls
ダウンロード完了: jpx_margin_data\xls\mtdailyk2026041700.xls
データ公表日: 2026-04-17
取得件数: 268件
CSV保存: jpx_margin_data\csv\margin_20260417.csv
PKL保存: jpx_margin_data\margin_history.pkl (268行)
完了! 合計履歴: 268行「既存履歴:」の行がありません。これは load_history() がPKLを見つけられなかったことを意味します。
原因は作業ディレクトリ(カレントディレクトリ)の違いです。タスクスケジューラから実行すると作業ディレクトリが C:\Windows\System32 などになるため、スクリプト内の相対パスでPKLを探すと別の場所を参照してしまいます。
根本的な解決策
スクリプト側でパスを絶対パスにします。__file__ を基準にすることで、どこから実行されても同じ場所を参照できます。
from pathlib import Path
# 修正前(相対パス)
DATA_DIR = Path("jpx_margin_data")
# 修正後(スクリプト自身の場所を基準)
DATA_DIR = Path(__file__).parent / "jpx_margin_data"batファイル側で cd /d %~dp0 を書いていても、Pythonスクリプト内で相対パスを使うと同じ問題が起きます。スクリプト側を修正するのが根本解決です。
ERRORLEVELが取れない問題と正しいbatの書き方
最初のbatでは goto :check_result を使ってエラーチェックを分岐させていました。しかしこれだと ERRORLEVEL がリセットされてしまい、Pythonがエラーで終了してもSUCCESSとログに書かれてしまうことがありました。
REM NG: gotoを挟むとERRORLEVELがリセットされる場合がある
py "%BASEDIR%jpx_margin_collector.py" >> "%LOGFILE%" 2>&1
goto :check_result
:check_result
if %ERRORLEVEL% EQU 0 ( ... )goto は不要です。Pythonの実行直後に if %ERRORLEVEL% で判定するだけでOKです。また、pause や「完了しました」のメッセージはタスクスケジューラ実行時には誰も見ないので、ログだけに絞るのがシンプルです。
@echo off
setlocal
cd /d %~dp0
set LOGFILE=%~dp0jpx_margin_collector_bat.log
echo [%DATE% %TIME%] ===== pipeline start ===== >> "%LOGFILE%"
where py >nul 2>&1
if %ERRORLEVEL% NEQ 0 (
echo [%DATE% %TIME%] ERROR: Python not found >> "%LOGFILE%"
exit /b 1
)
py "%~dp0jpx_margin_collector.py" >> "%LOGFILE%" 2>&1
if %ERRORLEVEL% EQU 0 (
echo [%DATE% %TIME%] SUCCESS >> "%LOGFILE%"
) else (
echo [%DATE% %TIME%] ERROR code=%ERRORLEVEL% >> "%LOGFILE%"
)
exit /b %ERRORLEVEL%ログで原因を特定する
自動実行が正常に動いているかは、ログファイルを確認するのが一番確実です。正常なログはこのようになります。
[2026/04/20 17:40:00] ===== pipeline start =====
JPXサイトからURLを取得中...
URL: https://www.jpx.co.jp/.../mtdailyk2026041700.xls
ダウンロード完了: jpx_margin_data\xls\mtdailyk2026041700.xls
データ公表日: 2026-04-17
取得件数: 268件
CSV保存: jpx_margin_data\csv\margin_20260417.csv
既存履歴: 273行 / 日付: [2026-04-16]
PKL保存: jpx_margin_data\margin_history.pkl (541行)
完了! 合計履歴: 541行
PKL: jpx_margin_data\margin_history.pkl
CSV: jpx_margin_data\csv\margin_20260417.csv
[2026/04/20 17:40:05] SUCCESS「既存履歴: 273行」という行があれば、前日のデータを正しく読み込めています。この行がなければ作業ディレクトリの問題です。
PKL→CSV変換を自動化に組み込む
HTMLダッシュボード(後の記事で解説)はブラウザで動くため、PKLを直接読めません。CSVに変換する必要があります。最初は別スクリプト(pkl_to_csv.py)として切り出していましたが、毎日の実行に自動で組み込む方が管理が楽なので、jpx_margin_collector.py の末尾に追記しました。
# collect() 関数の最後に追加
df_combined.to_csv(
DATA_DIR / "history.csv",
index=False,
encoding="utf-8-sig"
)
print(f" CSV(全履歴): {DATA_DIR / 'history.csv'}")これで毎日の自動実行時に PKL と CSV の両方が最新状態に保たれます。
なぜ utf-8-sig なのか
Windows の Excel でCSVを開いたときに文字化けしないよう、BOM付きUTF-8(utf-8-sig)で出力しています。Pythonやブラウザで読み込む場合は通常の utf-8 でも問題ありません。
なお、最初に「既存のPKLからCSVを変換したい」というケースでは、コマンドプロンプトで以下のように実行できます。Windowsの python3 -c はセミコロン区切りで複数行を渡すと引用符の扱いでエラーになりやすいため、小さなスクリプトファイルに書いて実行する方が確実です。
# pkl_to_csv.py
import pickle
import pandas as pd
with open("jpx_margin_data/margin_history.pkl", "rb") as f:
df = pickle.load(f)
df.to_csv(
"jpx_margin_data/history.csv",
index=False,
encoding="utf-8-sig"
)
print(f"{len(df)}行を出力しました")cd /d E:\temp\stocksoftware\jpx_margin_data
py pkl_to_csv.py2つの「更新日」を区別する設計
ダッシュボードのヘッダに「更新日」を表示しているのですが、実は2種類の日付を区別することにしました。
| 表示ラベル | 内容 | 取得元 |
|---|---|---|
| 更新: | システム最終処理日(batが動いた日) | JavaScriptの new Date()(ページロード時の当日) |
| データ最新: | CSVに含まれる最新のデータ公表日 | CSVの「データ公表日」列の最大値 |
この2つを区別することで、「システムは動いているが、JPXがまだデータを公開していない」「週末で更新がない」といった状況を判断しやすくなります。
// データ最新取得日 = CSVの最新データ公表日
document.getElementById("data-date").textContent =
dates[dates.length - 1] || "-";
// 更新日 = システム最終処理日(ページを開いた日 = 今日)
const today = new Date();
const yy = today.getFullYear();
const mm = String(today.getMonth() + 1).padStart(2, '0');
const dd = String(today.getDate()).padStart(2, '0');
document.getElementById("update-time").textContent =
`${yy}-${mm}-${dd}`;完成した自動実行フロー全体像
ここまでの修正を加えた後の自動実行フローをまとめます。
毎日の自動実行フロー
- タスクスケジューラが指定時刻(例:17:40)にbatファイルを起動
- batが
cd /d %~dp0でbat自身のディレクトリに移動 - batが
py jpx_margin_collector.pyを実行、出力をログファイルに追記 - スクリプトがJPXページをスクレイピングしてXLSのURLを取得
- XLSをダウンロード・パース、PKLに日次蓄積
- PKLをCSVに変換(
history.csv)して同フォルダに保存 - batがERRORLEVELを確認してSUCCESS/ERRORをログに記録
ファイル配置の最終形
stocksoftware/
└── jpx_margin_data/
├── jpx_margin_collector.py # メインスクリプト
├── run_jpx_margin_collector.bat # 自動実行bat
├── jpx_margin_collector_bat.log # 実行ログ
├── margin_history.pkl # 全履歴PKL
├── history.csv # HTMLビューア用CSV
├── margin_viewer.html # ダッシュボードHTML
├── xls/ # ダウンロードしたXLS
└── csv/ # 日付別CSV第3回では、蓄積したデータを使って需給シグナルを計算するロジックと、HTMLダッシュボードの構築について解説します。
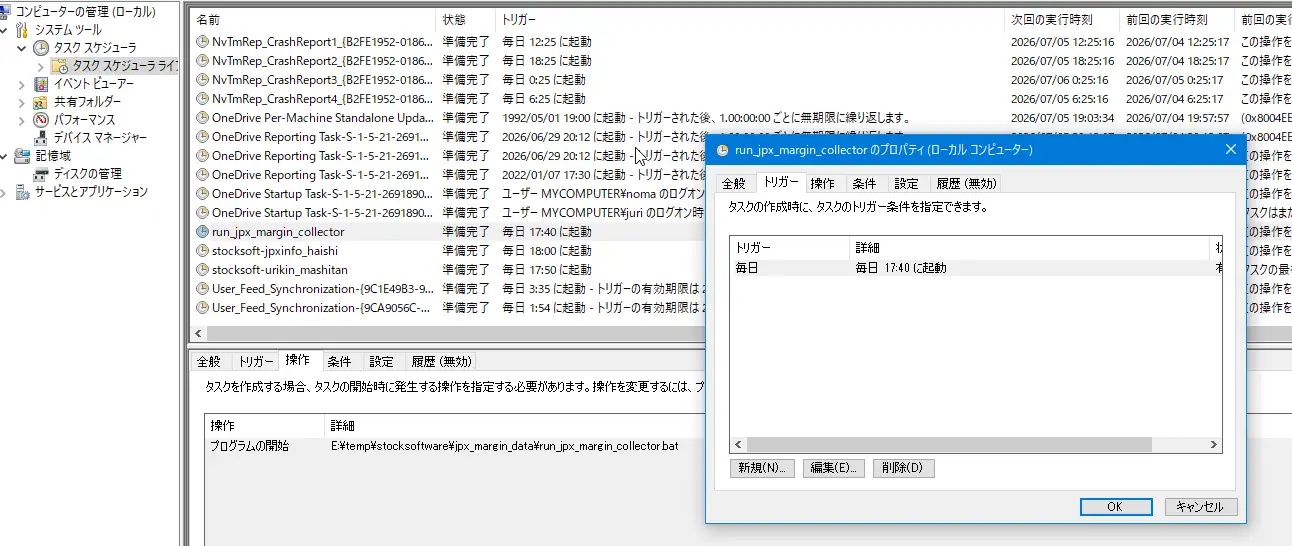
実際のタスクスケジューラ設定は下図のようなイメージです。
FAQ
タスクスケジューラでは動かないのに、batファイルをダブルクリックすると正常に動くのはなぜですか?
原因の多くは作業ディレクトリ(カレントディレクトリ)の違いです。タスクスケジューラから起動すると C:\Windows\System32 が基準になる場合があり、相対パスで指定したファイルを見つけられません。bat側で cd /d %~dp0 を実行し、Python側でも Path(__file__).parent を基準に絶対パスを組み立てることで、実行場所に依存しない構成にできます。
batファイルでPythonのエラーを正しく検知するにはどうすればよいですか?
Pythonの実行直後に ERRORLEVEL を確認するのが基本です。途中で goto や別のコマンドを実行すると終了コードが変わる場合があるため、py script.py の直後に if %ERRORLEVEL% EQU 0 で判定し、ログへSUCCESSまたはERRORを書き出す方法がおすすめです。
PKLファイルだけ保存すればCSVは不要ではありませんか?
Pythonだけで利用するならPKLでも十分ですが、ブラウザ上のHTMLやJavaScriptからはPKLを直接読み込めません。そのためWeb画面で利用する場合はCSVへの変換が必要になります。本記事では毎日の収集処理の最後にCSVも自動生成し、Pythonとブラウザの両方で同じデータを利用できるようにしています。
CSVを utf-8-sig で保存している理由は何ですか?
Windows版ExcelでCSVを直接開くと、通常のUTF-8では日本語が文字化けする場合があります。utf-8-sig(BOM付きUTF-8)で保存しておくと、Excelでも文字化けせず開けます。一方、Pythonやブラウザから利用するだけであれば通常のUTF-8でも問題ありません。
ログファイルにはどのような内容を残すべきですか?
少なくとも実行開始時刻、ダウンロードしたファイル名、取得件数、保存先、Pythonの標準出力・標準エラー出力、終了コード(SUCCESS/ERROR)は記録しておくことをおすすめします。タスクスケジューラでは画面にエラーが表示されないため、ログを充実させておくと原因の切り分けが非常に容易になります。