ローカルで完結していたものを公開サーバーへ届ける必要があった
第1回から第4回までで、JPXからのデータ収集・PKLへの履歴蓄積・需給シグナルの計算・HTMLダッシュボード表示まで、一通りの機能が自分のPC上では完成していました。しかし、ここまでの処理はすべてローカルのWindows機で完結しており、history.csvもダッシュボード用のHTMLも自分のPCの中にあるだけでした。
毎日自動でデータが更新されても、それを見られるのが自分のPCの前にいるときだけというのでは、せっかくの自動化の意味が半分になってしまいます。レンタルサーバー上に置いた公開ディレクトリへ、生成したファイルを自動で転送する処理が最後のピースとして必要でした。
ftplibでhistory.csvをアップロードする実装
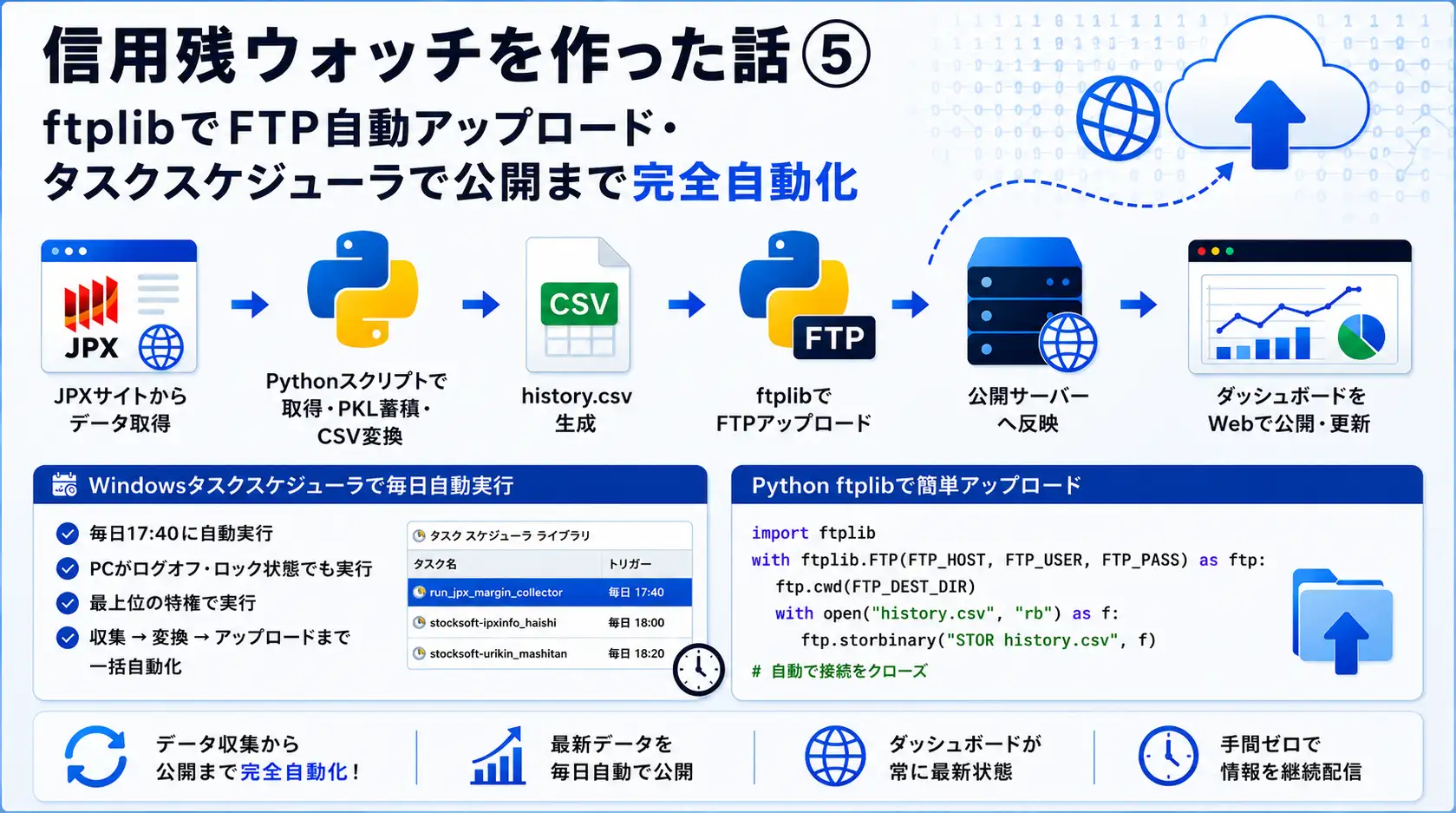
Pythonの標準ライブラリ ftplib を使えば、追加のパッケージを一切インストールせずにFTP転送ができます。今回作成した ftp_upload.py は、データ収集スクリプトとは別ファイルに切り出し、役割を分離しました。
FTPアップロード処理の実装
import ftplib
import os
def upload_to_ftp():
# --- FTP接続設定 ---
FTP_HOST = "www1172.conoha.ne.jp"
FTP_USER = "noma0124@jpx-info.com"
FTP_PASS = "********" # 本記事では伏字にしています
FTP_DEST_DIR = "/public_html/jpx-info.com/finance/jpx_margin_data/"
try:
with ftplib.FTP(FTP_HOST, FTP_USER, FTP_PASS) as ftp:
print("FTP接続成功")
# 指定された公開ディレクトリへ移動
ftp.cwd(FTP_DEST_DIR)
# history.csv のアップロード
file_name = "history.csv"
if os.path.exists(file_name):
with open(file_name, "rb") as f:
ftp.storbinary(f"STOR {file_name}", f)
print(f"Uploaded: {file_name}")
print("すべてのアップロードが完了しました。")
except Exception as e:
print(f"FTPエラーが発生しました: {e}")
if __name__ == "__main__":
upload_to_ftp()ポイントは with ftplib.FTP(...) as ftp: の形で接続することです。withブロックを抜けるときに自動でFTP接続をクローズしてくれるため、明示的なftp.quit()呼び出しを忘れる心配がありません。
また、ftp.cwd(FTP_DEST_DIR) で先にアップロード先のディレクトリへ移動しておくことで、その後のstorbinary()では相対的なファイル名(history.csv)だけを指定すればよくなり、コードがシンプルになります。
接続情報の扱いについて
掲載しているコードはホスト名・ユーザー名をそのまま書いていますが、実運用では公開リポジトリやブログに載せる際は伏字にするか、os.environ.get("FTP_PASS")のように環境変数から読み込む形に変更するのが安全です。今回はまず動かすことを優先し、後から分離する方針で進めました。
収集・変換・アップロードを1つのタスクにまとめる
第1回・第2回で作成した jpx_margin_collector.py(データ収集+PKL蓄積+CSV変換)に続けて、ftp_upload.pyを呼び出す形にすれば、batファイル1つで「収集→変換→公開」までが完了します。
@echo off
setlocal
cd /d %~dp0
set LOGFILE=%~dp0jpx_margin_collector_bat.log
echo [%DATE% %TIME%] ===== pipeline start ===== >> "%LOGFILE%"
REM 1. データ収集・PKL蓄積・CSV変換
py "%~dp0jpx_margin_collector.py" >> "%LOGFILE%" 2>&1
REM 2. FTPアップロード
py "%~dp0ftp_upload.py" >> "%LOGFILE%" 2>&1
if %ERRORLEVEL% EQU 0 (
echo [%DATE% %TIME%] SUCCESS >> "%LOGFILE%"
) else (
echo [%DATE% %TIME%] ERROR code=%ERRORLEVEL% >> "%LOGFILE%"
)
exit /b %ERRORLEVEL%
このbatファイルをタスクスケジューラに登録すれば、毎日決まった時刻にJPXからのデータ取得から公開サーバーへの反映まで、人の手を介さずに完結します。
タスクスケジューラ登録でハマったポイント
実際にタスクスケジューラへ登録する際、プロパティ画面の設定をいくつか見落として動作しないことがありました。
「タスク スケジューラ ライブラリ」での登録状況
コンピューターの管理画面から確認すると、run_jpx_margin_collector というタスクが毎日17:40に起動するよう登録されています。プロパティの「全般」タブでは、以下の設定が重要でした。
- ユーザーがログオンしているかどうかにかかわらず実行する:これがオフだと、PCがログオフ状態・ロック状態のときにタスクが実行されません
- 最上位の特権で実行する:ネットワーク処理(今回のFTP接続)を含むタスクでは、これにチェックが入っていないと権限不足で失敗することがあります
- パスワードを保存しない:チェックを入れると「ローカルコンピューターリソースのみ」に制限されるため、ネットワークドライブなどにアクセスする処理がある場合は外す必要があります
「トリガー」タブでは毎日17:40に起動する設定にしていますが、JPXの信用残データが更新されるタイミングを考慮し、確実にデータが公開された後の時刻に設定するのがポイントです。早すぎるとまだ前日のデータしか取得できません。
また、同じタスクスケジューラライブラリには stocksoft-jpxinfo_haishi(上場廃止ウォッチ)や stocksoft-urikin_mashitan(売禁ましたんウォッチ)といった、関連する別プロジェクトのタスクも並んで登録されています。1つのPC上で複数の自動収集プロジェクトを並行運用する場合、タスク名を見て何の処理か一目で分かるように命名しておくことが、後から見直す際に重要だと感じました。
運用してみて見えてきた改善点
実際にこの構成で運用を始めてみて、いくつか今後改善したいポイントが見えてきました。
パスワードのハードコーディングをやめたい
動作確認を優先したため、現状はFTPのパスワードがスクリプト内に直接書かれています。スクリプトファイルを誤って共有したり、Gitリポジトリにコミットしてしまったりするリスクがあるため、環境変数や.envファイル(gitignore対象)に分離するのが望ましい次のステップです。
アップロード失敗時のリトライ処理がない
現在の実装では、FTP接続に失敗した場合は例外をキャッチしてログに出力するだけで、リトライは行っていません。サーバー側の一時的な不調などでアップロードが失敗した場合、その日のデータは公開されないままになってしまいます。数回リトライしてから諦める、という処理を追加する余地があります。
アップロード前のバリデーション
収集処理が何らかの理由で異常終了し、history.csvが空や壊れた状態のままアップロードされてしまうと、公開中のダッシュボードが正しく表示されなくなるリスクがあります。アップロード前に行数チェックなどの簡易バリデーションを入れておくと安心です。
シリーズを通して作った仕組みの全体像
第1回から第5回までで、以下の一連の流れを完全に自動化できました。
完成した自動化フロー
- JPXサイトから個別銘柄信用取引残高のXLSを毎日自動ダウンロード(第1回)
- XLSをパースし、銘柄コードや日付の変換を行ってpandas DataFrameに整形(第1回)
- pickleで履歴を蓄積し、CSVにも変換(第1回・第2回)
- タスクスケジューラ+batファイルで上記処理を毎日自動実行(第2回)
- 蓄積したデータから踏み上げ候補・需給悪化警戒などのシグナルを計算(第3回)
- フィルタ・ソート・ページャーを備えたHTMLダッシュボードで一覧表示(第3回・第4回)
- 銘柄クリックで信用残の推移グラフとTradingViewの日足チャートを表示(第4回)
- ftplibで公開サーバーへ自動アップロードし、データ収集から公開までを完全自動化(第5回)
最初は「毎日の信用残データを手元に残しておきたい」という小さなモチベーションから始めましたが、自動収集・分析・可視化・公開までの一連の流れを自分の手で組み立てると、それぞれの工程で思いがけない落とし穴に当たります。今回のシリーズでまとめたカレントディレクトリの問題、ERRORLEVELの罠、cwdの基準位置のズレなどは、いずれも「ローカルでは動くのに自動実行だとおかしい」という形で表れる典型的なパターンでした。
同じようにPythonとタスクスケジューラで何かを自動化しようとしている方の参考になれば幸いです。
FAQ
PythonのftplibでFTPアップロードするにはどうすればいいですか?
標準ライブラリのftplibを使い、ftplib.FTP()で接続してftp.cwd()でアップロード先ディレクトリへ移動、ftp.storbinary()でファイルを転送します。withステートメントを使うと処理完了後に自動で接続をクローズできます。
タスクスケジューラに登録したタスクが動かないことがあるのはなぜですか?
タスクのプロパティで「ユーザーがログオンしているかどうかにかかわらず実行する」が選ばれていない場合、PCがログオフ状態だとタスクが実行されません。また「最上位の特権で実行する」のチェック漏れもネットワーク処理が失敗する原因になります。
FTPの接続情報(パスワードなど)をスクリプトに直接書いても大丈夫ですか?
動作確認の段階ではベタ書きしても動きますが、本番運用や他者に共有する可能性がある場合は環境変数や別の設定ファイルに分離し、スクリプト自体にパスワードを残さない設計にするのが望ましいです。