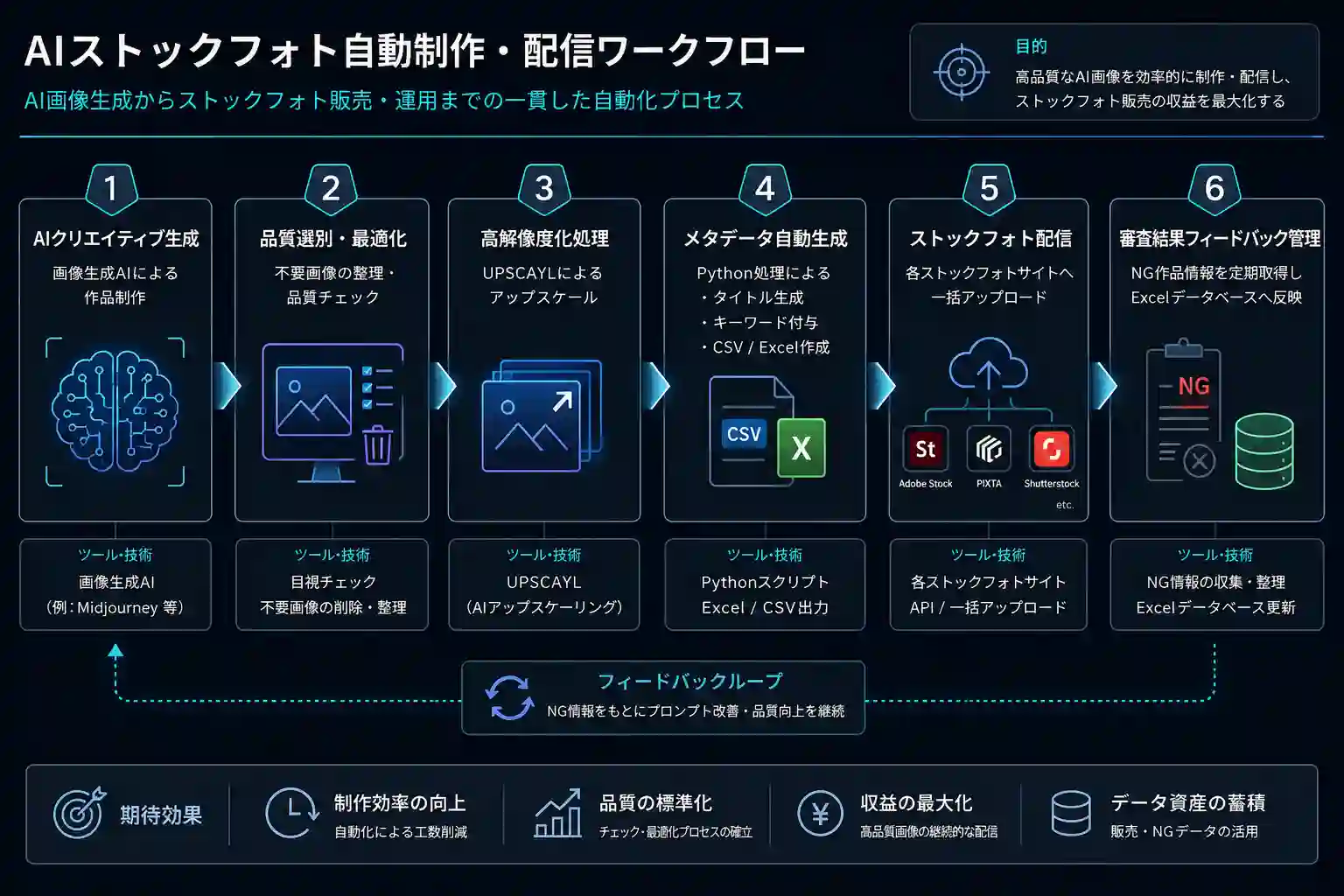
前記事では、CLIPを使った品質スコアの設計とExcel記録の仕組みを紹介しました。本記事ではその続きとして、ローカルPC移行・Ollamaによるメタデータ自動生成・Adobe Stock申請CSV出力までを解説します。
本記事の位置づけ(フロー④後半)
前記事はGoogle Colabでの実装でしたが、本記事では以下の拡張を行っています。
- 処理基盤をColabからローカルPCに移行
- Ollamaとmoondreamモデルによるタイトル・キーワード自動生成
- Adobe Stock申請用CSVの自動出力
- Excelへの2シート構成(スコア記録+申請データ)
Google ColabからローカルPCへの移行
ColabとローカルのCLIPスコア処理結果は数値的にほぼ同一ですが、「毎日使う」という運用の観点でローカルのほうが便利と判断しました。ブラウザを開いてColabに接続する手間がなく、batファイルをダブルクリックするだけで処理が始まります。
ローカルPCのスペック(GTX 1060 3GB・RAM 16GB)で動作するか確認したところ、CLIP処理はGPUで問題なく動作することを確認しました。専用VRAM 3GBに対し共有メモリも含めると最大11GBを活用できるため、思ったより余裕がありました。
| 処理 | Colab(T4) | ローカル(GTX 1060) |
|---|---|---|
| CLIP処理(50枚) | 約3〜5分 | 約15〜30分 |
| Ollama生成(50枚) | — | 約25〜50分 |
| 起動の手間 | ブラウザ起動が必要 | batファイル1クリック |
| 結果の数値差 | ほぼ同一(小数点4桁目以降の微差のみ) | |
環境構築:batファイル一発起動の設計
毎日使うツールとして、できる限り起動を簡単にする設計にしました。ファイル構成はシンプルな3点セットです。
ファイル構成
- setup.bat:初回のみ実行。ライブラリのインストールとOllamaモデルのダウンロードを自動化。
- run.bat:毎回の実行用。Ollamaサーバーを起動してからPythonスクリプトを呼び出す。
- stock_analyzer.py:メイン処理。設定エリアのパスを変更するだけで動作する。
環境構築の過程でいくつかトラブルに遭遇しました。batファイルの文字コード問題でコマンドが認識されないエラーが発生しましたが、日本語をすべて英語に統一することで解決しました。また、PythonとOllamaのパスが環境変数に登録されておらず、GUIから手動で追加する対応が必要でした。こういった「環境構築のつまずき」はローカル運用あるあるで、一度解決すればその後は快適に使えます。
Ollamaで画像を見てメタデータを自動生成
Adobe Stockへの申請には、ファイルごとに英語タイトル(200文字以内)とキーワード(最大49個)の入力が必要です。これを手動で行うのは非常に手間がかかります。
そこで、ローカルで無料で動くAI「Ollama」を使い、画像を見てタイトルとキーワードを自動生成する仕組みを実装しました。
モデルの選定では、当初qwen2.5vl:3b(日本語対応の視覚言語モデル)を試みましたが、VRAM 3GBでは画像認識時にメモリ不足でクラッシュしてしまいました。そこで、画像認識専用に設計された軽量モデルmoondreamに切り替えました。moondreamは必要VRAMが約1.5GBと少なく、GTX 1060でも安定して動作します。英語でのキーワード生成に特化しているという点でも、Adobe Stock向けとして適切な選択でした。
モデル選定のポイント
「日本語対応モデルだから良い」ではなく、「VRAMに収まるか」「英語キーワードを生成できるか」を優先しました。Adobe Stockのメタデータは英語が基本のため、英語特化モデルのほうが結果的に適切でした。
VRAMの競合問題とその解決策
実装の過程で、CLIPとOllamaを同時に動かすとVRAMが不足してOllamaがタイムアウトするという問題が発生しました。GTX 1060の専用VRAM 3GBはCLIP処理でほぼ使い切ってしまうため、Ollamaが追加でメモリを確保できない状態でした。
解決策として、処理を2フェーズに分離しました。
- フェーズ1:全画像のCLIP処理(処理2・3・4)を完了させる
- CLIPモデルをGPUメモリから完全に解放する
- フェーズ2:Ollamaが全VRAMを使えるようになってからメタデータ生成
また、Ollamaに送信する画像は512pxにリサイズしてから渡すことで、通信データ量を削減しています。元の4Kアップスケール画像をそのまま送るとbase64変換だけで数十MBになってしまい、処理時間が大幅に増加するためです。
Adobe Stock申請CSV自動出力
Adobe StockではCSVファイルをアップロードすることで、複数ファイルのメタデータを一括登録できます。必要な列はFilename・Title・Keywords・Category・Releasesの5項目です。
本ツールでは、Ollamaが生成したタイトルとキーワードを自動でCSV形式に変換して出力します。カテゴリは画像の内容から自動判定(人物・自然・ビジネス・食べ物・動物など)します。
出力されるファイル
- analysis_results.xlsx(シート1「解析結果」):処理2・3・4のスコアを追記
- analysis_results.xlsx(シート2「Stock申請CSV」):タイトル・キーワード・カテゴリを追記
- adobe_stock_upload.csv:Adobe Stockに直接アップロード可能なCSVファイル
実際に出力されたCSVの一部です。タイトルとキーワード49個が自動で入っています。
| Filename | Title | Keywords(抜粋) | Category |
|---|---|---|---|
| 0519 (18).jpg | Young Asian woman using smartphone indoors | woman, smartphone, asian, indoor, technology, portrait... | 1 |
完成した運用フローのまとめ
一連の実装を経て、審査前の作業が以下のフローで完結するようになりました。
- Upscayl処理済みの画像をフォルダに入れる
- run.bat をダブルクリックするだけ
- フェーズ1:全画像のCLIPスコアを自動算出
- フェーズ2:Ollamaが各画像を見てタイトル・キーワードを自動生成
- Excelに追記(既処理ファイルは自動スキップ)
- Adobe Stock申請用CSVが自動出力される
毎日の運用でかかる人手間
新しい画像をフォルダに入れてrun.batをダブルクリックするだけです。あとはPCが自動で処理します。処理中は別の作業ができます。
次のステップは、Adobe Stockへの申請後の審査OK・NG結果をExcelに記録する仕組みの構築です。審査結果とスコアを照合することで、どのような画像が通りやすいかの傾向分析が可能になります。この内容は別記事で紹介予定です。
FAQ
Ollamaとは何ですか?
ローカルPCでAIモデルを無料で動かすためのツールです。インターネット接続なしでもLLMを利用でき、画像認識対応モデルを使えばタイトルやキーワードの自動生成も可能です。
Adobe StockのCSVアップロードとは何ですか?
Adobe Stockでは、Filename・Title・Keywords・CategoryをCSV形式で一括アップロードできます。手動入力の手間を大幅に削減できます。
GTX 1060でAI処理は動きますか?
CLIP処理は問題なく動作します。ただし画像認識モデルはVRAMを多く消費するため、モデル選定が重要です。本記事ではmoondreamという軽量モデルを採用しました。